Informer Basics
Informer Support Links
Datasets vs Ad Hoc Reports
The big difference between Ad Hoc Report and Datasets are that the data in a Dataset is persisted, whereas the data in an Ad Hoc Report is temporary. The reason this is important is that a single dataset could drive multiple users Charts and exports, whereas an Ad Hoc Report would need to be run for each user. This means hitting the database and waiting for the query behind the Ad Hoc report to run.
Datasets also bring a number of other benefits.
- Single source of truth - A single dataset can provide data to multiple charts and exports for many users, thus making sure all users are seeing the same data.
- Less stress on the database - Given that the data in a Dataset is persisted. The dataset can be scheduled to reload one or more times a day and then reports will access this data instead of running each time a report is requested.
- Stored Visuals - You can create common visuals and store them on the Dataset. This allows end users to quickly see the data in the dataset visualized.
- Stored Filters - You can store common filters making it easy for users to filter the data with a single click.
- Comparison boards and Dashboards - Datasets are needed to be able to create and use Comparison boards and Dashboards
Creating a Dataset from an Ad Hoc Report
A dataset and an Ad-Hoc report have many of the same features, however the dataset is the preferred format if you plan on scheduling the query to run at certain intervals and what multiple users to be able to use reports built from the dataset.
For example, if you had 10 users who needed the data from a query and it was built as an Ad-Hoc report, the database would be hit 10 times to produce the data. Once for each user running the report.
However, if the query was build as a Dataset and was scheduled to be reloaded every 6 hours, then those 10 users could access the data with just a single run of the query against the DB every 6 hours.
This is a change from Informer 4, so you will see that all of the base reports and imported reports come into Informer 5 as Ad-Hoc reports. Luckily, it is very easy to convert these Ad-Hoc reports into Datasets.
Step 1
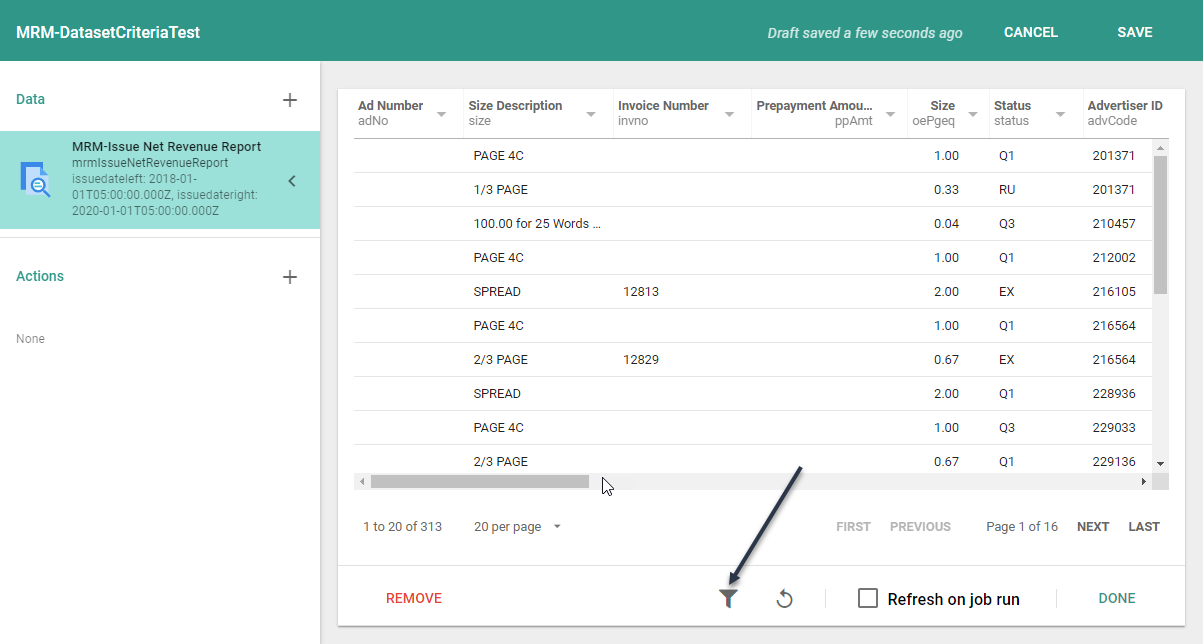
Find the report you want to covert to a Dataset, open it and run it.
This is very important, as the report must have data in it for you to get the "Create Dataset" option.
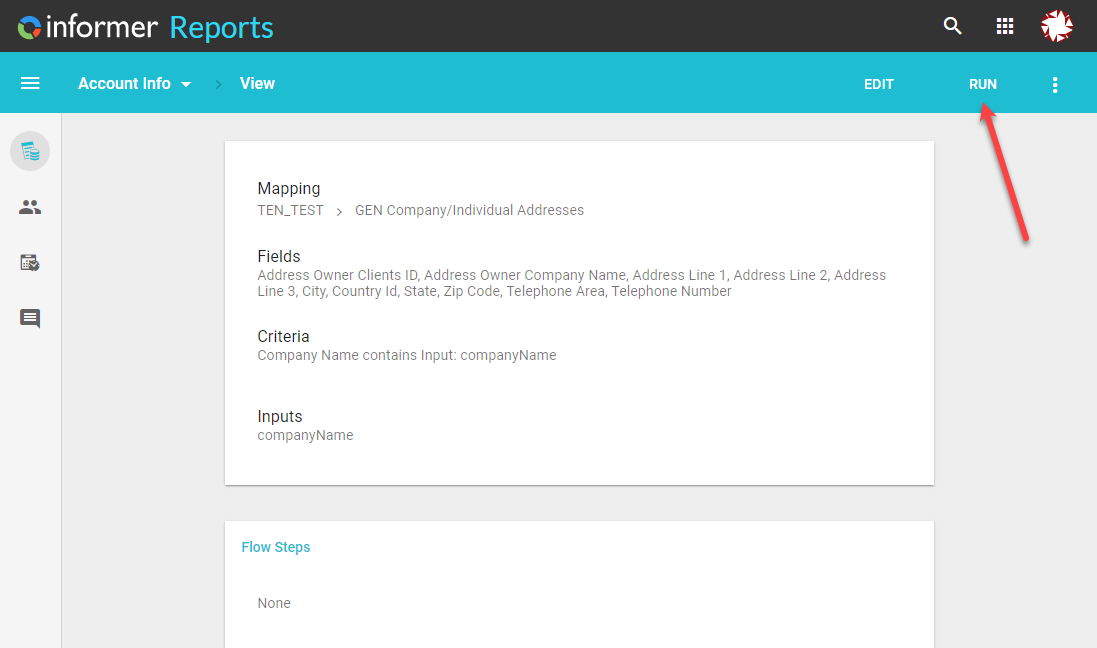
Step 2
Click on the vertical 3 dots in the right corner and choose "Create Dataset"
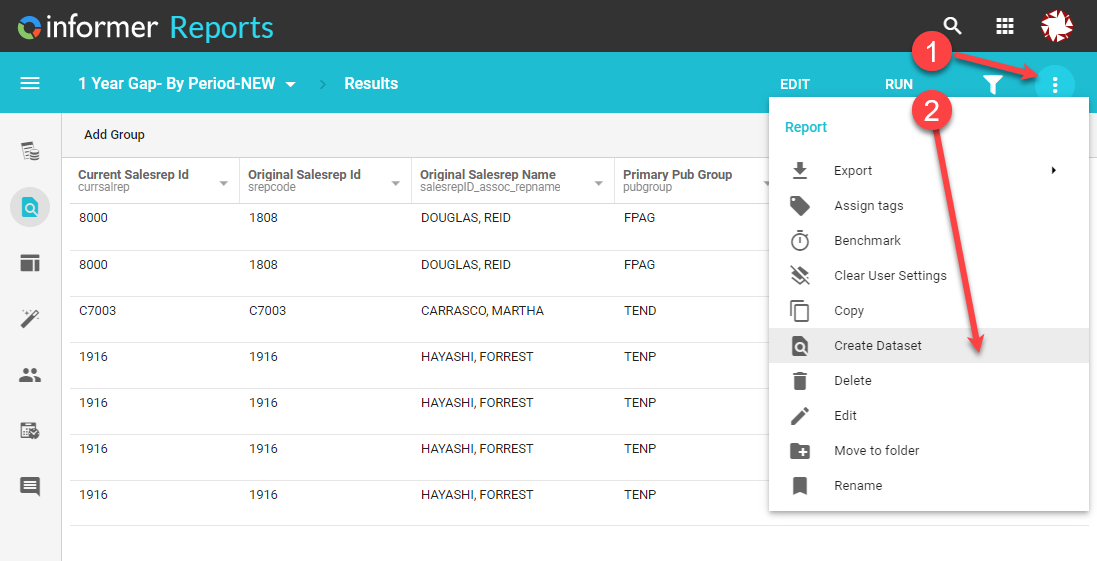
This will bring up a dialog where you can name your Dataset and give it a description.
Once done with that you will be taken to the Dataset view of the report you converted.
Informer Tips
Current Month - YOY Using Criteria
To pull data for the current month from both this year and last year from a dataset, you can use the following Criteria

This is accomplished by creating a Group in the Criteria section of a query.
Since you want to get data from both the current month and the current month from the previous year, make sure to mark the group as "Match one of"
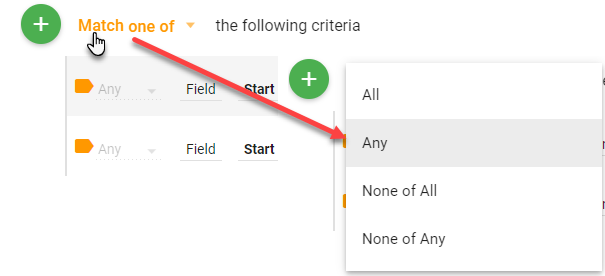
Next, add criteria and choose the date field you want to filter on. The first criteria will be using the inclusive between comparison. This will allow you to choose two values for the between to match on.
To make this dynamic, so that you do not need to change the criteria every month, you can use informer keywords to populate our between values. You can access a list of the keywords from within Informer as well:
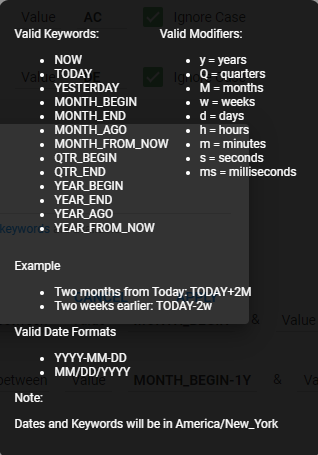
You will populate the two values with MONTH_BEGIN and MONTH_END. This will instruct informer to look at today's date to determine what is the starting and ending of the month.
This will give us the current month's data, but we also want last years data for the same month.
Add a new Criteria row and using the same date field as the other criteria do another inclusive between comparison, but this time instruct informer to pull last years data. Using Informer's keywords MONTH_BEGIN-1Y and MONTH_END-1Y.
Notice all that was needed was using the Years modifier and specifying how many years to subtract.
Current Month - YOY Using a Calculated Field
A calculated field won't limit your dataset, but you can use it to create a field using JavaScript to pull only specific data.
This field doesn't make sense, but, create a Flow Step -> Calculated Field:
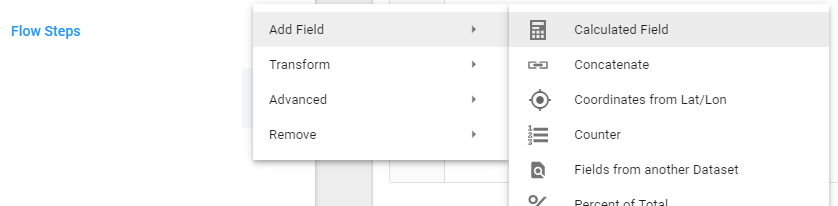
If you want to have a field that only contains priceActAmout for rows with a startDate of 2018, do this:
if(moment(startDate).year() === moment().year()-1) {
priceActAmt
} else {
0
}
See the Informer JavaScript Docs for more examples of Calculated Fields.
Viewing a Dataset Query
When creating complex criteria, it is sometimes nice to be able to see the query that Informer constructs. This will allow you to verify that your criteria is actually doing what you want it to.
The following can be done when editing a Dataset or Report.
Just click on the ellipses near the Query title and choose View code
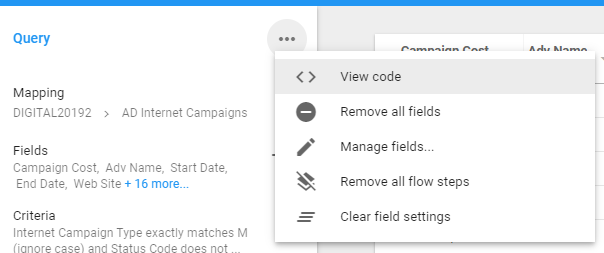
This will pop up a window called Query code. It won't look pretty, but you will be able to see how Informer has interpreted how you built your criteria.
Here is an example:
SELECT INET.CAMPAIGNS WITH (EVAL "OCONV(CAMPAIGN.TYPE,'MCU')" = "M" AND EVAL "OCONV(STATUS.CODE,'MCU')" NE "AC" AND EVAL "OCONV(STATUS.CODE,'MCU')" NE "DE" AND EVAL "OCONV(STATUS.CODE,'MCU')" NE "KI" AND EVAL "OCONV(STATUS.CODE,'MCU')" UNLIKE "Q..." AND ((START.DATE >= "11/01/2019" AND START.DATE <= "11/30/2019") OR (START.DATE >= "11/01/2018" AND START.DATE <= "11/30/2018")))
LIST INET.CAMPAIGNS EVAL "CHAR(244):CHAR(171):CONVERT(CHAR(253),CHAR(250),CONVERT(CHAR(252),CHAR(249),CONVERT(CHAR(251),CHAR(248),CONVERT(CHAR(32),CHAR(7),CONVERT(CHAR(4),CHAR(245),CONVERT(CHAR(13),CHAR(247),CONVERT(CHAR(10),CHAR(246),SUBR('-OCONVS',CAMPAIGN.ID,'MD00'):CHAR(166):ADV.NAME:CHAR(166):AGENCY.NAME:CHAR(166):WEB.GROUP:CHAR(166):STATUS.CODE:CHAR(166):SUBR('-OCONVS',START.DATE,'D4/'):CHAR(166):SUBR('-OCONVS',END.DATE,'D4/'):CHAR(166):SUBR('-OCONVS',COST,'MD22'):CHAR(166):SUBR('-OCONVS',COMMISSION,'MD22'):CHAR(166):SUBR('ESC.AT.V5',WEB.SITE):CHAR(166):SUBR('ESC.AT.V5',PRICE.DESC):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.START.DATE,'D4/')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.END.DATE,'D4/')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.PER.UNIT,'MD55')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.QTY,'MD00')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.EXT,'MD22')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.ACTUAL.IMPS,'MD00')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.ACT.AMT,'MD22')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',TRANS('INF_INET.ORDERS',PRICE.LINEID,'ACT.AMT','X'),'MD22')):CHAR(166):STATUS.DESC:CHAR(166):WEB.GROUP.NAME))))))):CHAR(187)" CNV "" FMT "80L" ID.SUP COUNT.SUP COL.SPCS 0 HDR.SUP COL.SUP REQUIRE.SELECT
You can go to Instant SQL Formatter to clean up the above query ... a little.
If you look at the Current Month - YOY Example, we create a group and did two inclusive between comparisons on Start Date. If you look at the SQL below, you will see that part of the code start at line 6.
SELECT inet.campaigns with (eval "OCONV(CAMPAIGN.TYPE,'MCU')" = "M"
AND eval "OCONV(STATUS.CODE,'MCU')" ne "AC"
AND eval "OCONV(STATUS.CODE,'MCU')" ne "DE"
AND eval "OCONV(STATUS.CODE,'MCU')" ne "KI"
AND eval "OCONV(STATUS.CODE,'MCU')" unlike "Q..."
AND ((
start.date >= "11/01/2019"
AND start.date <= "11/30/2019")
OR (
start.date >= "11/01/2018"
AND start.date <= "11/30/2018"))) list inet.campaigns eval "CHAR(244):CHAR(171):CONVERT(CHAR(253),CHAR(250),CONVERT(CHAR(252),CHAR(249),CONVERT(CHAR(251),CHAR(248),CONVERT(CHAR(32),CHAR(7),CONVERT(CHAR(4),CHAR(245),CONVERT(CHAR(13),CHAR(247),CONVERT(CHAR(10),CHAR(246),SUBR('-OCONVS',CAMPAIGN.ID,'MD00'):CHAR(166):ADV.NAME:CHAR(166):AGENCY.NAME:CHAR(166):WEB.GROUP:CHAR(166):STATUS.CODE:CHAR(166):SUBR('-OCONVS',START.DATE,'D4/'):CHAR(166):SUBR('-OCONVS',END.DATE,'D4/'):CHAR(166):SUBR('-OCONVS',COST,'MD22'):CHAR(166):SUBR('-OCONVS',COMMISSION,'MD22'):CHAR(166):SUBR('ESC.AT.V5',WEB.SITE):CHAR(166):SUBR('ESC.AT.V5',PRICE.DESC):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.START.DATE,'D4/')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.END.DATE,'D4/')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.PER.UNIT,'MD55')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.QTY,'MD00')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.EXT,'MD22')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.ACTUAL.IMPS,'MD00')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',PRICE.ACT.AMT,'MD22')):CHAR(166):SUBR('ESC.AT.V5',SUBR('-OCONVS',TRANS('INF_INET.ORDERS',PRICE.LINEID,'ACT.AMT','X'),'MD22')):CHAR(166):STATUS.DESC:CHAR(166):WEB.GROUP.NAME))))))):CHAR(187)" cnv "" fmt "80L" id.sup count.sup col.spcs 0 hdr.sup col.sup require.SELECT
Loading External Attribute Data
There are two ways to load attribute data (Excel, CSV, etc) for us in Informer:
- Direct Spreadsheet Load into a Dataset - This is a "quick and dirty" way to quickly get data from a spreadsheet into Informer. This is only recommended for data that you will not be loading often and is generally NOT the way to get external data into Informer.
- Create a Workspace for External Data - This is the recommended way of importing external data. It is more stable and easier to use than option 1.
Regardless of the method that you use to import the data, you will need to make sure that you know how the data that you are going to import will join to the existing Informer data.
An example would be period dates if your corporation has periods that don't follow the calendar. in this case you would create a spreadsheet that might look something like this:
| ext_period_date | ext_period_year | ext_period | ext_period_week |
|---|---|---|---|
| 01/01/2021 | 2021 | 1 | 1 |
| 01/02/2021 | 2021 | 1 | 1 |
| 01/03/2021 | 2021 | 1 | 1 |
| ... | ... | ... | ... |
| 03/04/2021 | 2021 | 3 | 1 |
In the above case, you would join the ext_period_date to whatever date field in your report needed to be expressed in your corporate periods.
Excel To Dataset Direct
Just a reminder, this is NOT the recommended way to bring in external data, but is a quick way to test how data might link.
One example of external data that would work would be extra customer attributes that are not in the main database, old account number, other name, etc.
Here is an easy example. I have a dataset in Informer with a bunch of information, one of them being the Agency Name. I also have an external spreadsheet with the Agency Name and an Agency Alias.
The end goal is to link the spreadsheet to the dataset on Agency Name.
To do this, you first must create a dataset from your external spreadsheet. You can accomplish this in a number of ways, here are two:
Go to the Datasets page in Informer and drag and drop your Excel file
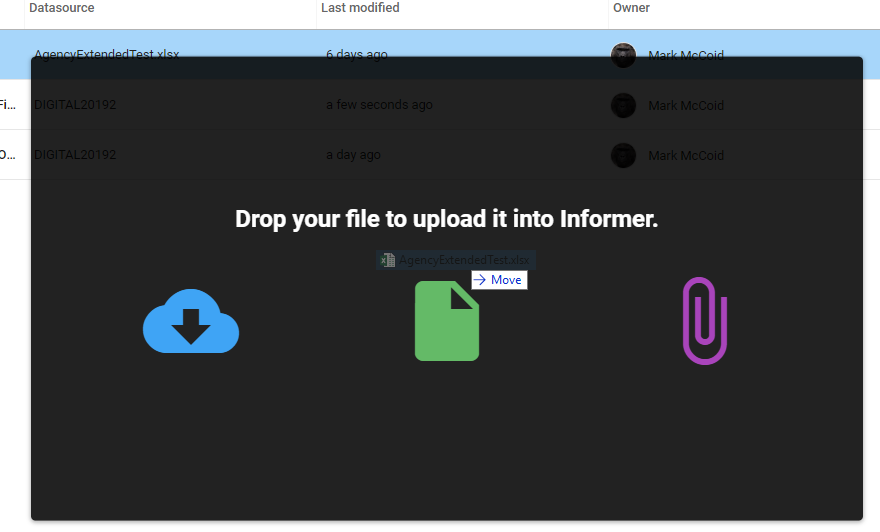
You will the dialog above, simply drop the file here.
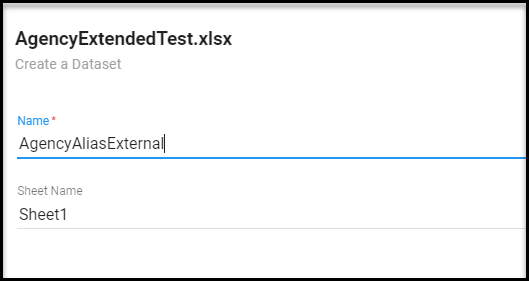
Give the dataset a name and choose the sheet (this is an excel file) that the data is located on.
OR, Click on the New Dataset button and choose upload a file:
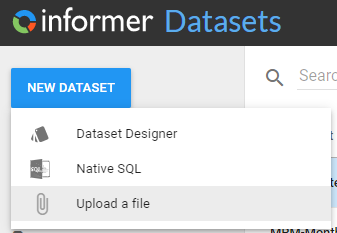
Then choose a file and fill in the Dataset name and Sheet name where data is located.
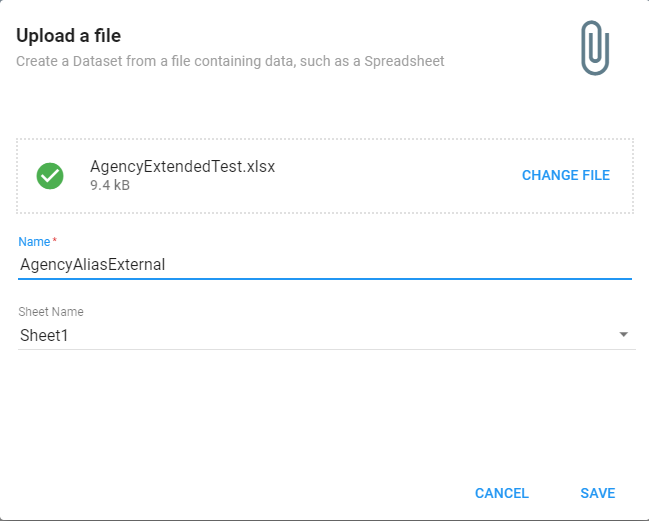
Click Save.
This will upload the data in the external file and create a new Dataset. You will see it in your list of Datasets:
Link Data to Another Dataset
To get the Agency Alias into another Dataset, simply open the Dataset that you want to append the external data to and create a field using the Flow Step, Add Field/Fields from another Dataset
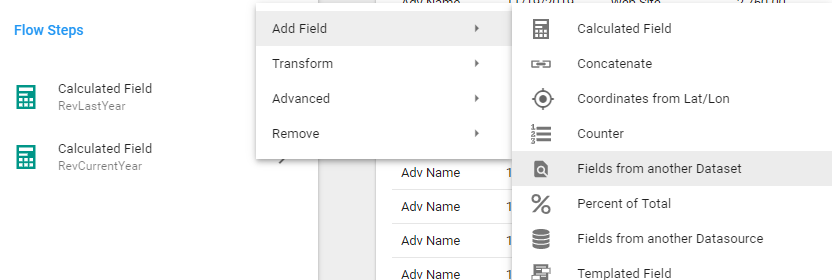
This Flow will have you select the dataset where the target field resides (AgencyAliasExternal Dataset) and then you must link these Datasets by choosing the fields from each dataset that will create the link. In our case, it is simply the Agency Name.
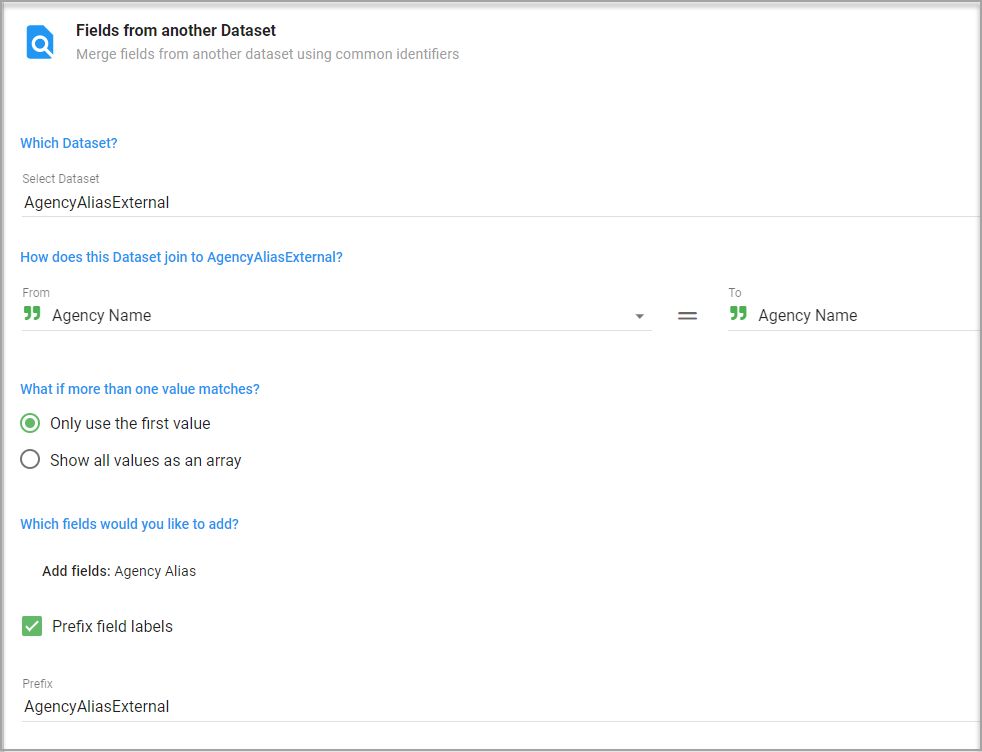
The other important setting is choosing the fields you would like to. Click and add the fields that you want. In this example, it is just the Agency Alias.
The What if more than one value matches? option can be left as Only use the first value.
The Prefix field labels setting allows you to add a prefix to these import fields so that you can better identify them as coming from another dataset. It is optional.
Using Workspaces
A workspace is a Datasource that holds mappings of any external data that you want to import. You can think of a Workspace as a database or your external spreadsheets.
First you need to create a Workspace to load your external data into. Go to the Datasources area in Informer, click on NEW DATASOURCE and then choose Workspace.
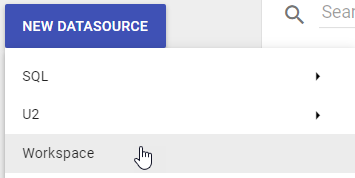
Enter a name for the workspace. How about External Data. You can house multiple excel files or other external data source within a single datasource.
Once you create Workspace, you will have an UPLOAD DATA button in the middle of the screen. Press this button and either click on Choose Files or drop the file containing your external data into the gray square.
Recommended File structure:
- CSV Format - Instead of Excel, CSV format is preferred.
- Header Names - Make them lowercase and if the header has multiple words, separate each work with an underscore.
- Period Date becomes period_date
Once you drop your file, it will load and analyze it. If you haven't followed the above rules, you may see this screen:

If so, click on Configure and then on the magic wand next to the Field Name label. This will simply rename your header names into a form that Informer can use.
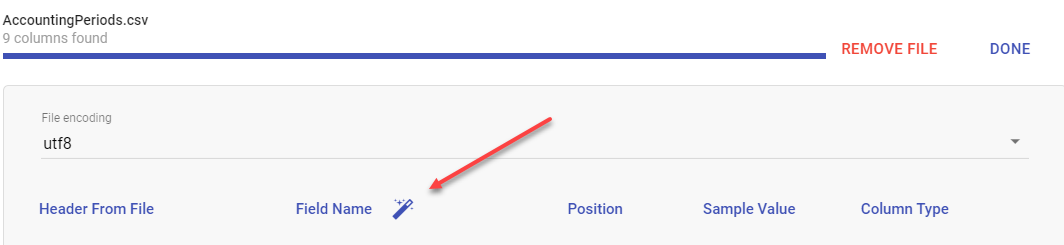
Lastly, click Import. You now have a new mapping in a Datasource named External Data that can be used just like any other mapping.
This means that you could create a Dataset with any mapping in your External Data Datasource OR you could join the field to an existing Dataset using the flow step Fields from another Datasource.
Flow Steps
Normalize
Splits array values into individual rows for each value in the array.
I tested on a dataset that had multiple array fields in it and when I normalized on all of the array fields, it "lined" up the arrays.
Without Normalize flow step:
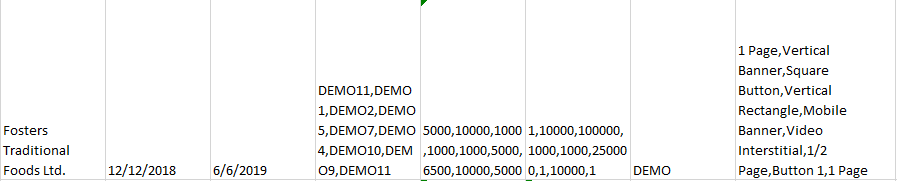
With the Normalize flow step:

If your query contains a one to many join (think order to order details type query), Normalize will duplicate the "one" fields for each "many".
If you don't normalize, you will get something that looks like you have multivalued fields.
Filters
Filters can be found in many places within Informer. Their main purpose is to further limit the data that is loaded in a Dataset or Ad Hoc Report.
Filters applied from different areas will work a little differently and it is important to understand how they differ.
To start let's look at the different ways to use filters on a Dashboard Report.
Variables / User Fields
User Fields can be created on the Administration panel by click on the User Fields option.
Once a user field has been created, you can assign it to a user(s) and give it a value. Then you can access any user field in either criteria or filters to limit the data based on the value in these users fields.
Filtering - Variables. You can setup certain variables that are unique for each user. For example, Department could be a variable that would be each users department so when they ran the filter it would automatically filter by their department.
Filters - Using the Dates
Date Keywords
Using Date keywords in your filters will allow you to get dynamic date filtering. Meaning this filtering will update based on the current date when the filter is run.
Here are the keywords:
WEEK_BEGIN, WEEK_END are keywords not listed in box above, but are available to use.
All keywords resolve to a single date. For example TODAY will be today's date. YEAR_BEGIN will be January 1st of the current year. I believe NOW is the only keyword to incorporate the current time.
The Keywords by themselves would allow us to do a whole lot, but the modifiers really add power.
The modifiers allow you to take the date returned by the Keyword and change it by years, quarters, months, weeks or days.
For example, if the filter needed is Start of the Year two years ago through the Current Start of the Year. If today's date is 5/5/2020, the filter being requested is:
01/01/2018 through 01/01/2020
Using the modifiers we can accomplish this as follows:
- YEAR_BEGIN-2y = 01/01/2018
- YEAR_BEGIN = 01/01/2020
You can have one modifier modifying each Date Keyword. You cannot do something like this: YEAR_BEGIN-2y+2m
To accomplish this you would instead do:
YEAR_BEGIN-22m
BUG ALERT - I did find an issue when trying to use YEAR_BEGIN with no modifiers. It didn't return anything. To make it return the current YEAR_BEGIN adding a + or - after it seemed to work: YEAR_BEGIN+
To create a filter using Date Keywords, select the Date keyword option, which will show in your filter options if you are on a field typed as Date.
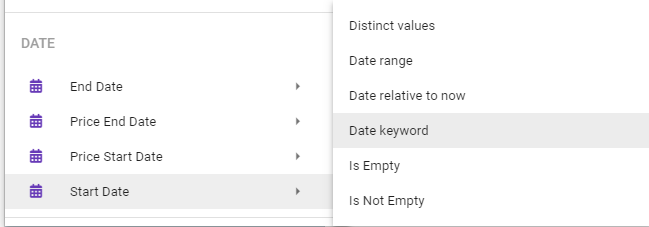
This will present you with a side bar area where you can build your filter.
When building your filter, another feature of Date keywords that you need to understand is how to tell your filter how to filter on the date keyword you create. You have the following options:
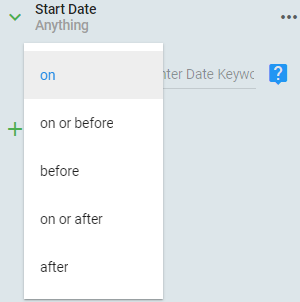
In the example below, assume the Date Keyword is YEAR_BEGIN and it will return a date of 01/01/2020 and the field being filtered is StartDate
on - Only return records that match the date returned by your Date Keyword.
StartDate = 01/01/2020
on or before - Return records where dates are less than or equal to the date returned by your Date Keyword.
StartDate <= 01/01/2020
before - Return records where dates are less than the date returned by your Date Keyword.
StartDate < 01/01/2020
on or after - Return records where dates are greater than or equal to the date returned by your Date Keyword.
StartDate >= 01/01/2020
after - Return records where dates are greater than the date returned by your Date Keyword.
StartDate > 01/01/2020
You can create multiple rows in your filter to achieve the filter that you want.
An example would be creating a filter that would select all dates from the beginning of the previous year, to the end of the current year. Please note there are multiple ways to structure this filter, I will only present one.
If today's date is 5/5/2020, our filter should do the following
StartDate >=01/01/2019 and StartDate < 01/01/2021
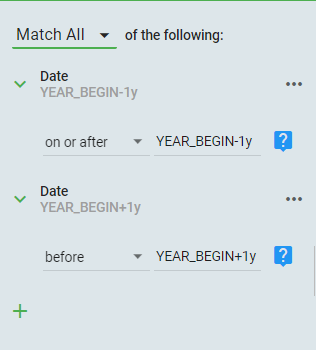
Date Relative to Now
Date Relative to Now creates a filter that lets you look into the past or future in relation to today's date. The first field will be either 'Next' or 'Past'. The middle field is a positive integer that needs the final field to tell the filter if it will be days, weeks, months or years.
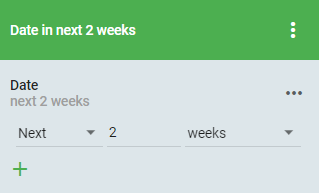
Keep in mind that when filtering for the Next/Past of anything, it doesn't take the current date to be part of the Next/Past selection.
Past WILL include today's date in the filtered dates
Next WILL NOT include today's date in the filtered dates
Some examples based on Today's Date of 1/13/2020
- Past 2 Days - Returns 1/11/2020-1/13/2020
- Past 2 Weeks - Returns 12/30/2019-1/13/2020
- Next 2 Months Returns 1/14/2020 - 3/31/2020 - Notice it returned the Next full 2 months
Date Range
The tried and true date range is simply that. Enter a starting and an ending date range to filter on.
Distinct Values
Allows filtering by Years, Months, etc. If the filter needed is Nov and Dec of 2019, 2020, Distinct Values will get you there.
When you choose Distinct Values on a Date field, you will initially be presented with the years available in the date field to select. However, by clicking on the ellipses you will have the option to change the date period to something else.
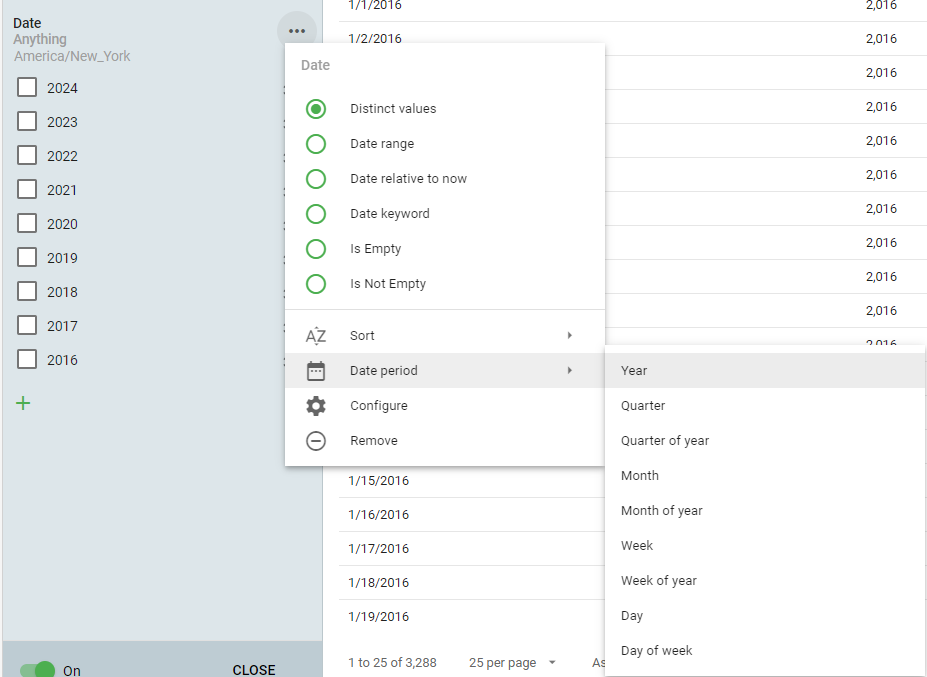
In our example, filter by Nov and Dec of 2019 and 2020, you would need to add two Distinct value filters. The first for the years and the second for the months. It would like like this:

Filters - Reports
When you filter any type of report, there are two places where you can filter the report.
The two places are at the top level of the report and the other is when you are inside and editing the report.

When filtering at this level, it is only for your user. Only your user will see it.
If you want all users to see the filter, you will need to click on the Edit button and set your filter in this area.
Once you click on the Edit button, click on the vertical ellipsis by the Dataset name and choose Custom Filter
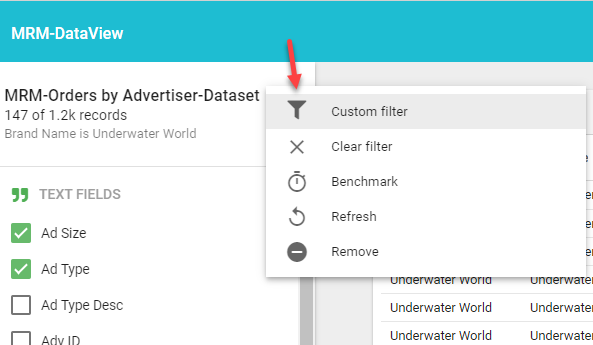
After you have created your filter, you can click on the Apply button.
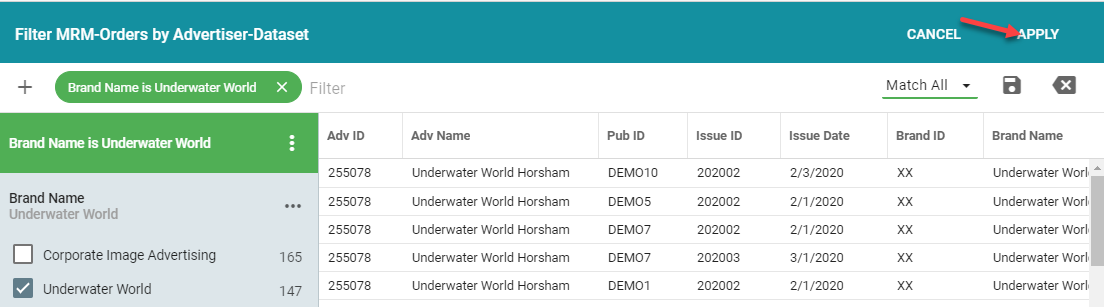
This will "bake in" the filter to your report. The other option would be to Save the filter by clicking on the save icon. However, the user who created and saved the filter and other super users will be the only one who will be able to see and apply the filter.
Saving the filter is useful if you have a complex filter that you want saved on your report. Sometimes, to create a complex filter, you need saved portions of it.
Saving Report Filters
Ad Hoc Reports
If you save a filter on an Ad Hoc report, it will be saved for your user. I have found no way to share this with any other users.
Other Reports based on Datasets
If you need to be able to share filters, you will want to make sure your data is coming from a Dataset versus an Ad Hoc Report.
Important: The Reports AND the Datasets feeding the reports must BOTH be shared with the Team or Users who you want to be able to interact with it.
Whenever a user (or the creator) of the report creates a filter in the report, it will be saved as a private filter on the underlying dataset. If you want other users to see the filter, you will need to open the Dataset and mark the filter as public.
Datasets
The data in a Dataset will be persisted. Meaning that once loaded, it will be available for future use, while the Ad Hoc query's data is dumped after it is done being used.
Persisted but not updated data would work for historical data, but for reporting that requires current data the dataset data must be refreshed at certain intervals to be useful.
You can do this by scheduling a job to run to refresh your datasets.
Copying Datasets
It is very easy to make a copy of an existing Dataset. Simply click on the vertical ellipses in the upper right hand corner of the Dataset screen and choose Copy. Give your copy a new name.
This will NOT copy any Visuals or Filters that you have stored in the Dataset. To get Filters and/or Visuals copied into a new dataset, following the Bundle Copy method below.
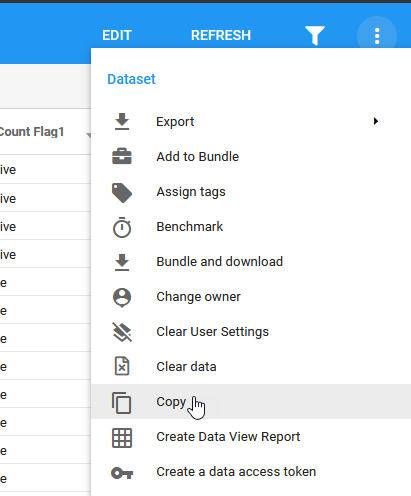
Bundle Copy a Dataset
You will want to use this method to copy a Dataset if you want to retain the Filters and Visuals that exist on the Dataset being copied.
Jobs & Emails
Jobs are the Informer way to take some sort of action.
- Emails are sent as part of a Jobs.
- Jobs are also used to schedule the reload datasets.
You can pair the reloading with Actions like emailing, however, you don't have to. Each dataset in a Job has a check box "Refresh on job run" that will determine if the dataset will be refreshed before the other actions in the Job are run.
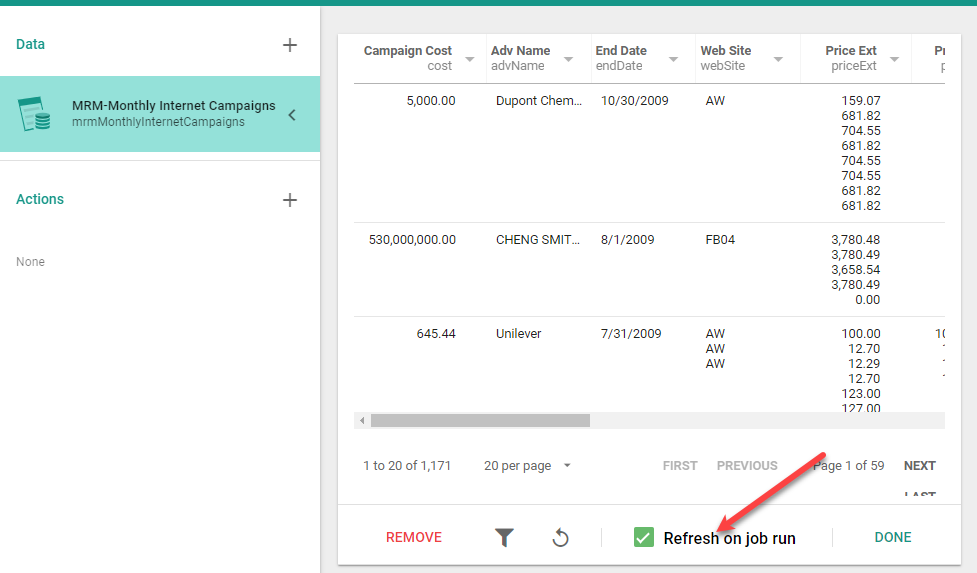
A job is made up of two parts, the Data and the Actions.
You can have a Job with just Data (probably for a reload) or just Actions, you don't need both.
Job Data Options
The data for a job can be either a Dataset or a Query. The Query being one of your Ad-Hoc Reports.
You can have multiple Data objects in a single job. This would allow you to refresh both data objects as well as send email that included data from both Data objects.
Job Actions
You have five actions that you can perform in a job. They are:
- Send an Email - Sends an email to users that enter. This is an option where a single email will be generated and you will have to fill out the email addresses that the email is going to. This is useful for reports that you know who the recipient will be
- Send an email burst - An email burst uses the data in the dataset to get the email addresses to send emails and data to. This is what I would call a loop and reduce, since it will not only use an email field in the dataset to determine who to send the email to, but will also reduce the data so that the email recipient only gets the data they are "associated" with.
- Send to FTP - This option is NOT available. If you try to use it, it will not work.
- Send to file system - This option will let you export to a Naviga designated FTP site. See Exporting To The File System
- Export Saved List - this will create list in a Datasource
Email Burst Job Action
An email burst uses the data in the dataset to get the email addresses to send emails and data to.
This is what I would call a loop and reduce, since it will not only use an email field in the dataset to determine who to send the email to, but will also reduce the data so that the email recipient only gets the data they are "associated" with.
You can choose to attach the data associated with the user email and/or include the full set of data.
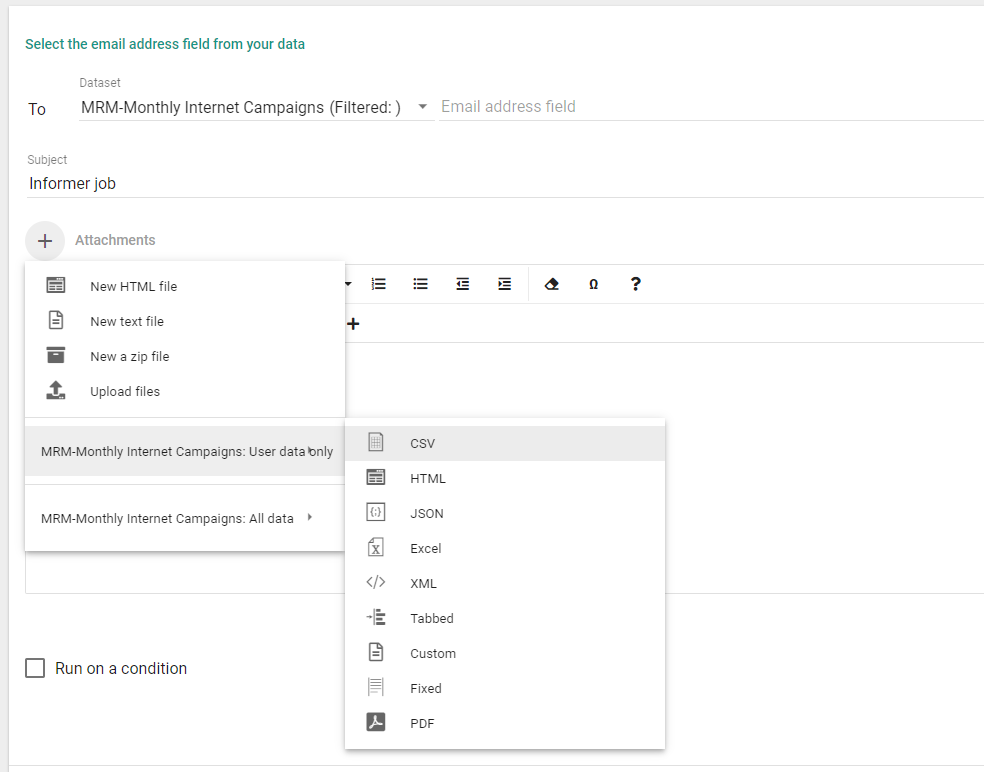
Creating Dynamic Export File Names
When attaching a CSV or Excel file to an email or when sending to the File System or FTP, it is sometimes useful to be able to make the name unique based on the run.
The option that you have in an Informer Job is to introduce date information into the file name. You will be able to do this when you add an attachment to a Job Action.
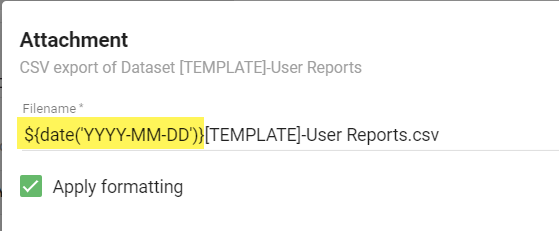
As noted in the screenshot above, you can use the following syntax to add a date component to your file name:
${date('YYYY-MM-DD')}
The format string above ('YYYY-MM-DD'), is a Moment JS formatting string. You can read more about it:
Official Moment JS Docs on Formatting
Alerts for Failed Jobs
There is no direct way to get an email or other notification that a job has failed, however, you can create a new Datasource in Informer that points to the metadata database that informer maintains.
This database contains tables that hold information about the Informer system, including jobs.
Setup Informer Metadata Datasource
Export a Pivot Table via a Job
When you create a Pivot Table, you can manually export it to a CSV file. You cannot export it to any other format like PDF, etc.
You also will NOT have an option to export a pivot table through a Job.
Jobs only have access to the top level data. Meaning any visualizations you create on a Dataset or through an Ad Hoc Report will not be available in a Job for export.
You can however, in a round about way, make your visualization available to the end users who receive emails via your Jobs.
What is the End Result
Instead of email the users an Excel file or CSV file, we will be emailing them a link to a visual on a Dataset. The "Visual" will be of the Pivot table.
Once they have access this Pivot table, they will be able to export it at that point to a CSV or Excel file.
Step 1
The first step is to create the Pivot Table that you want your end users to have access to.
This can be done directly on the Dataset or through a Dataview report. However, even if you create the visual through a Dataview report, it will still be saved on the Dataset.
From a Dataview report, create the desired Pivot table and then click on the horizontal ellipsis in the right hand corner and choose "Save pivot to visuals"
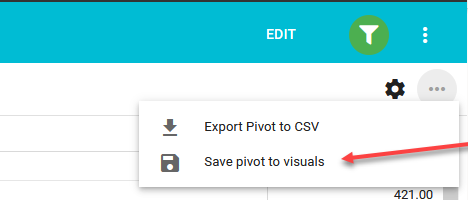
This will not save the pivot anywhere in the report, but instead will save it to the underlying Dataset that is driving the report.
You can then view the saved visual by opening the Dataset and clicking on the "Visuals" icon:
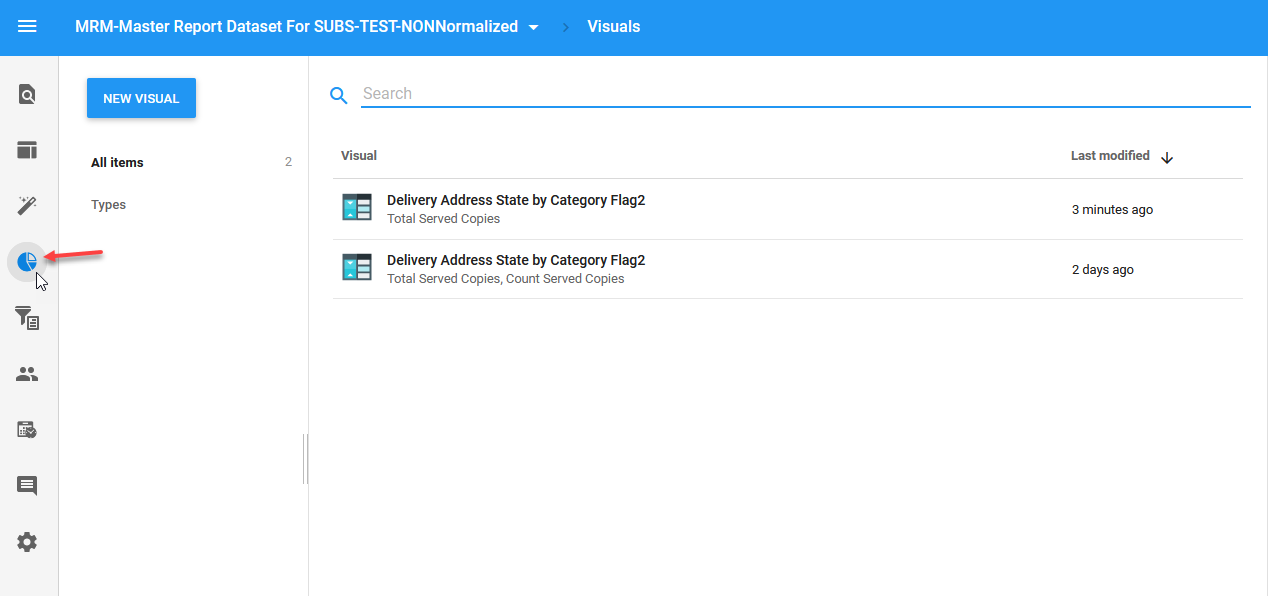
You can also create new visuals from this area also.
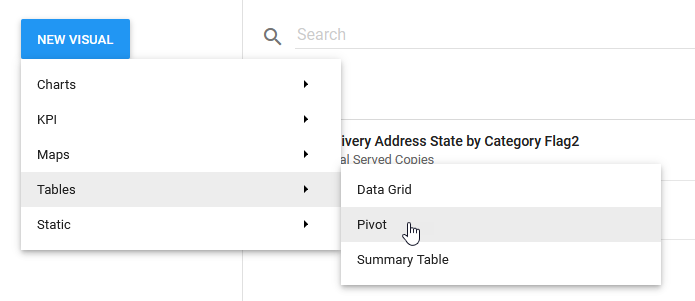
Just click on the New Visual / Tables / Pivot:
Step 2
Now that you have create a visual, you will need to "Generate external link" for the visual.
From the Visuals page, select the visual you want to export by simply clicking once on the visual and then clicking on the horizontal ellipses in the bottom right and select "Generate external link"
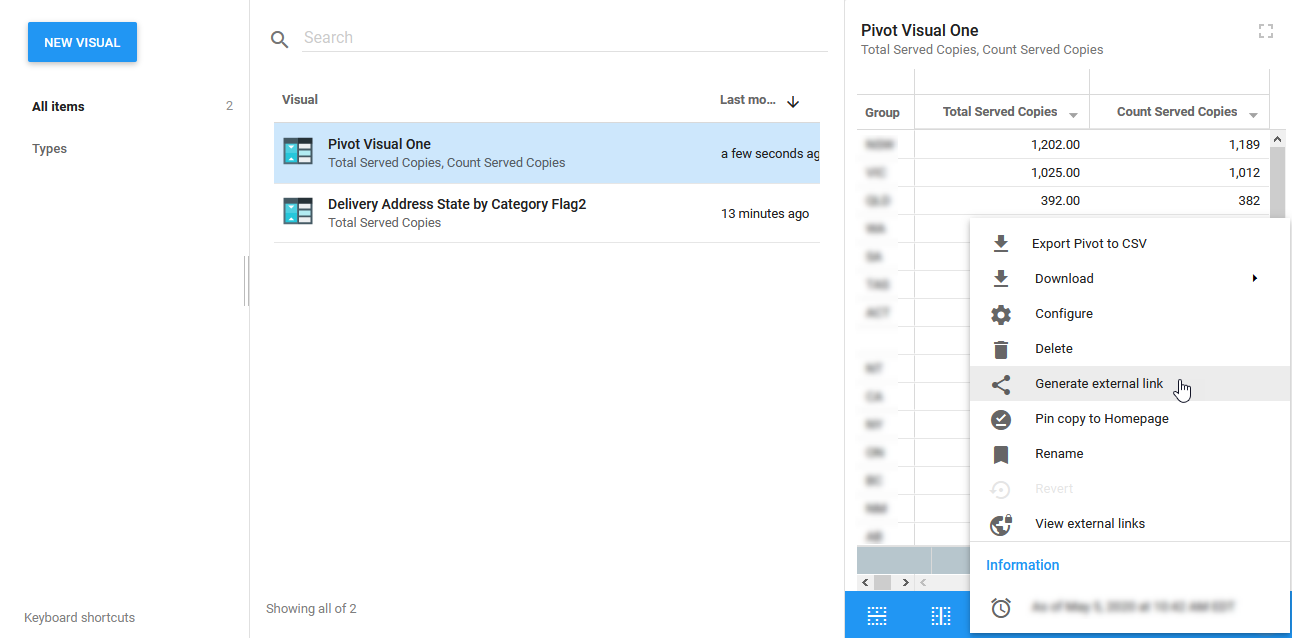
This will bring up the following dialog:
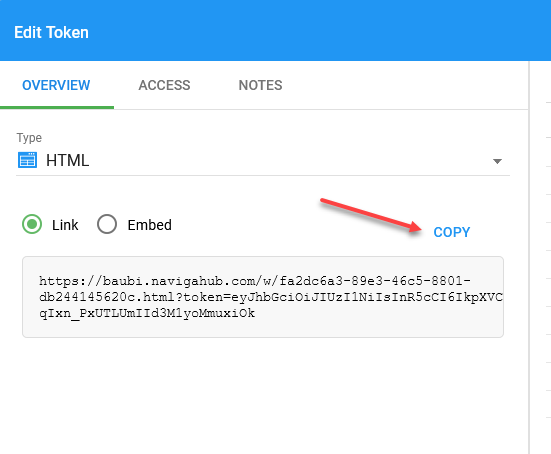
Click on Copy and store this link in notepad for later use.
Step 3
Get that link to whomever needs it. This can be done via a Job that runs everytime the dataset refreshes, or you could send it out once to the people who need it and let them know that every day around X time, there will be new data.
If you set up a job, it is as simple as putting the Dataset in a job and then setting up an email action to
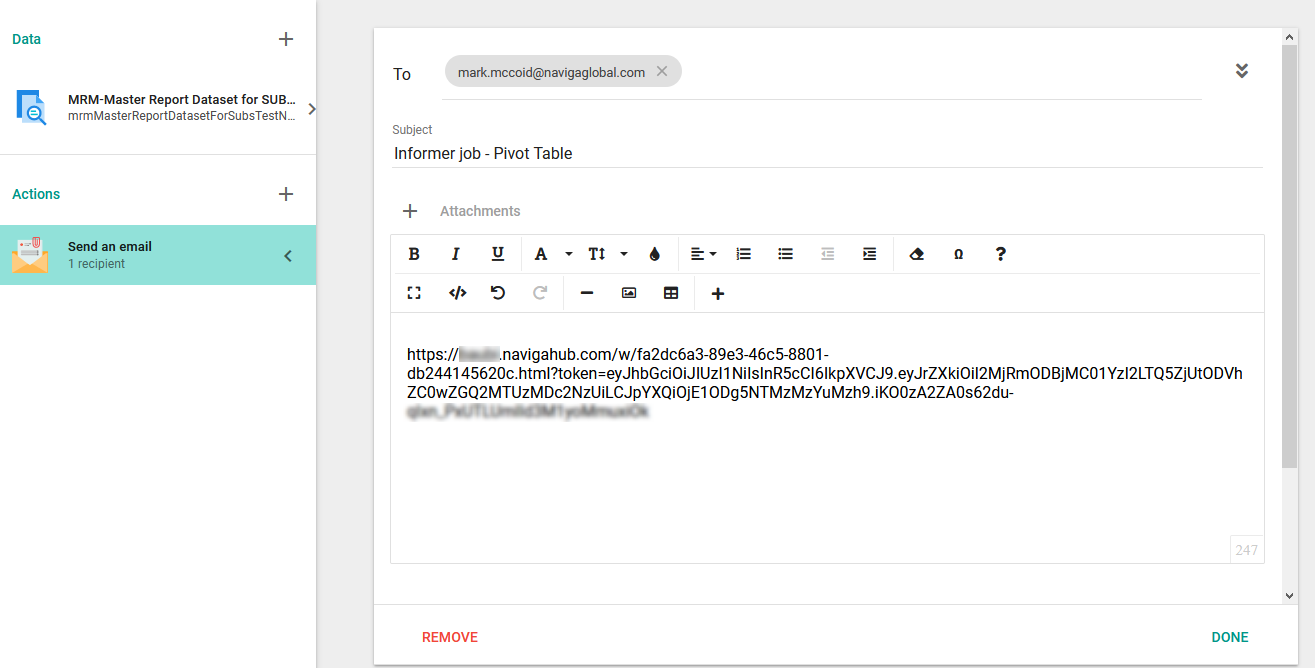
Exporting To File System-FTP
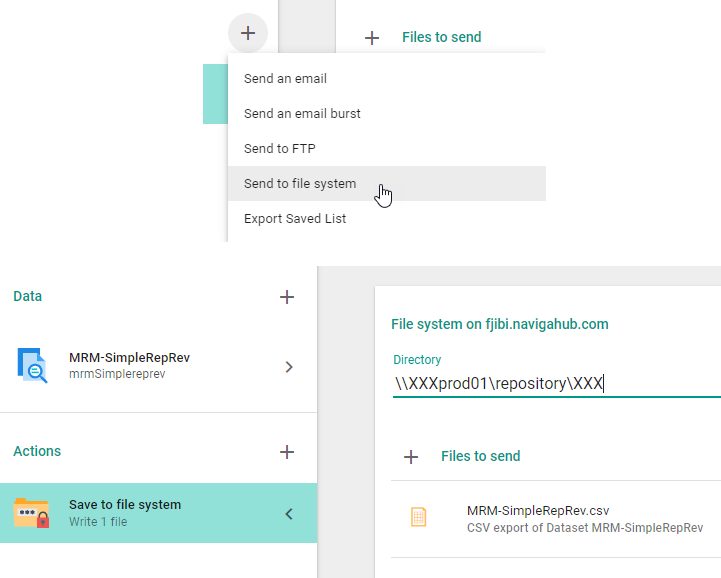
When creating actions for a job, you may want to send your data to an FTP site and you will see an option "Send to FTP". However, this option does NOT work because of security restrictions.
What you can do is instead choose to "Send to file system". This option will send to an FTP site that you will have access to.
In the image below, you will see that you need to the directory where you want the file to be located. You will replace the "XXX"'s with your company's three character company code.
\\XXXprod01\repository\XXX
To access the FTP site where these files will be stored, you will need to use a program like Filezilla or other FTP software using the following details:
Host: ftp_useeast.navigahub.com or ftp_uswest.navigahub.com or http://ftp_euwest.navigahub.com/
Port: 22
Encryption: "Require explicit FTP over TLS"
Username/Password: Ask your support rep for this information.
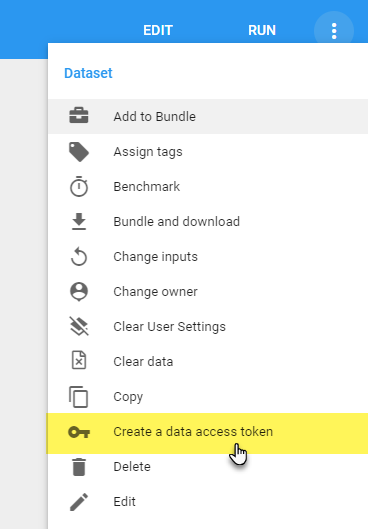
Data Access Tokens
Data Access Tokens allow you to access your Dataset from a command line interface using cURL or HTTPie.
You can create a Data Access Token by clicking on the Action menu in a Dataset and choosing "Create a data access token".
You can also use the curl output to access the data via a browser or in a program that supports rest APIs.
Here is an example of using cURL with a Data Access Token:
curl "https://digital20192.msglcloud.com:8082/api/datasets/cafe1b00-9544-4799-a06a-184ebc4e4bd9/export/json?token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXkiOiIyNTk0ZWNjNi1mYmY1LTRlZTgtYmJmNy0zOTEyNDNhMWU4NjkiLCJpYXQiOjE1ODA3NDQ3MzIuMzIzfQ.GPmK56XqmiEww_D6kSWZHh1FNSeqaadePg706u1qkEg"
If you just take what is in quotes, you can paste into a browser or into another application.
Output can be in JSON, XML or CSV.
Here is a sample of JSON output from a sample Dataset:
[
{
"name_id_assoc_companyName": "MERLE NORMAN COSMETICS",
"salesrep_id_assoc_repName": [
"Nora Smith"
],
"id": "MENO*LOC1*16",
"advName": "MERLE NORMAN COSMETICS",
"agencyName": "",
"brandName": "DOMESTIC",
"baseCost": 1140
},
{
"name_id_assoc_companyName": "BMW of North America, LLC",
"salesrep_id_assoc_repName": [
"Wayne Burrows"
],
"id": "244008*A1*48",
"advName": "BMW of North America, LLC",
"agencyName": "Mediavest/Starcom",
"brandName": "3 Series",
"baseCost": 42962.7
},
{
"name_id_assoc_companyName": "BIOMARIS USA",
"salesrep_id_assoc_repName": [
"LUCIOUS, LOLA"
],
"id": "BIUS.1*LOC1*4",
"advName": "BIOMARIS USA",
"agencyName": "",
"brandName": "DOMESTIC",
"baseCost": 1908.68
},
...
]
Copying Dataset to Different Datasource
If you develop a Dataset in one Datasource and want to move or copy it to a new Datasource, you will need to follow these steps.
NOTE: There is currently a "bug" in Informer which causes you any saved Visuals and Filters on the dataset to be lost when performing the copy. Unfortunately, this is the only way to point a Dataset to a different Datasource.
Step 1
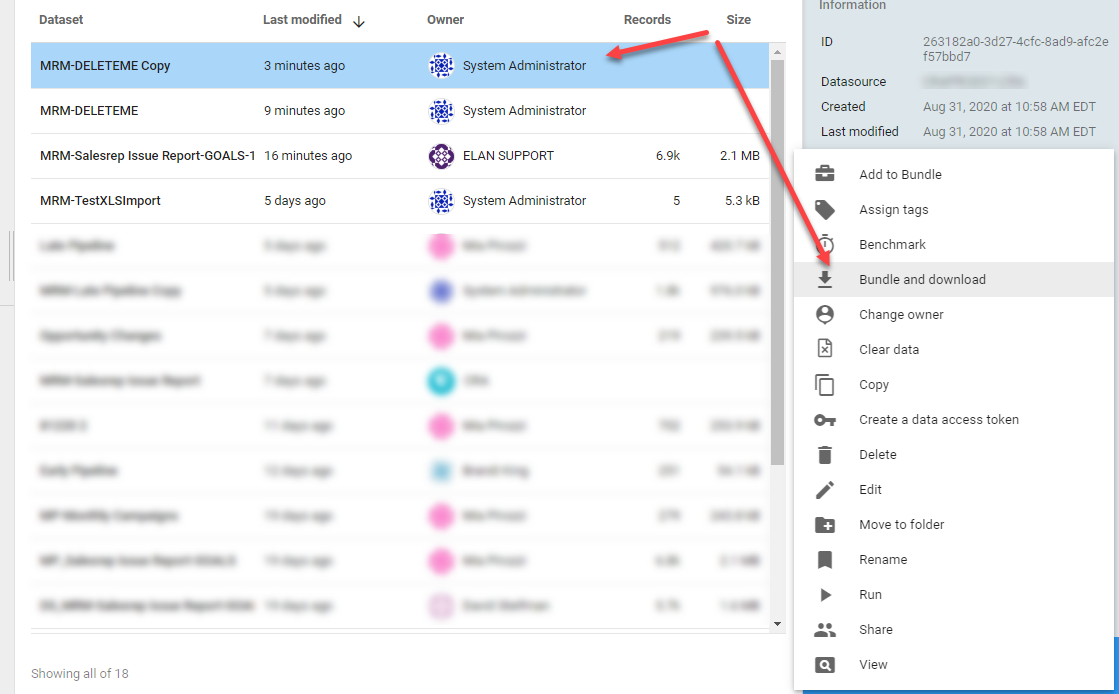
Make a copy of the Dataset in question. This is very important, you must have a COPY of the dataset.
Step 2
Highlight the copied Dataset, click on the Actions menu and choose Bundle and download
Step 3
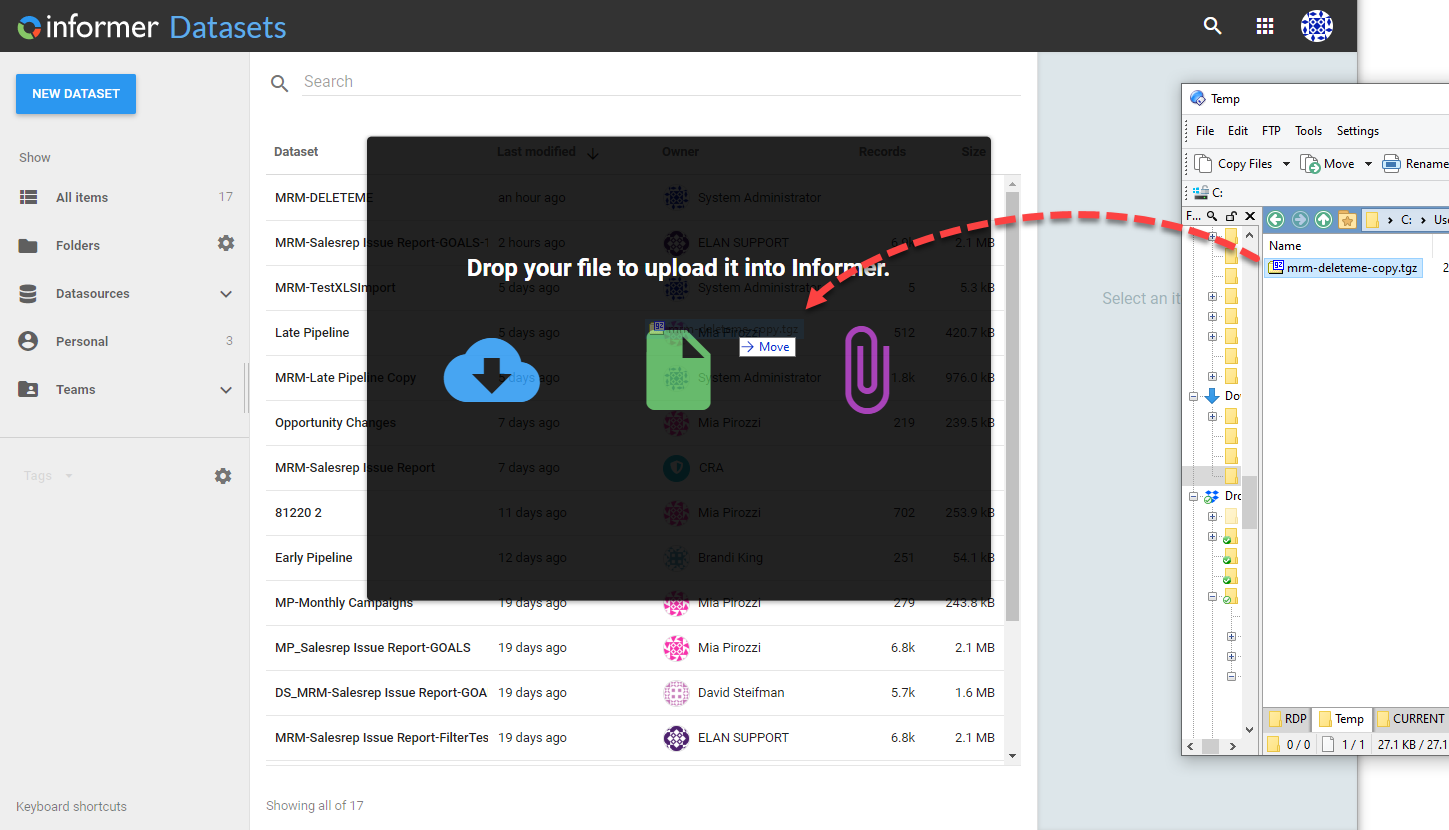
Delete the Dataset that you just bundled and downloaded. You need to do this so that in the next step when we reimport the dataset (even though we will point to a different Datasource) it doesn't conflict with an existing dataset.
Step 4
The Bundle and download step will have created a tgz file in your download directory. This is the file that you will need to drag and drop onto the Dataset window.
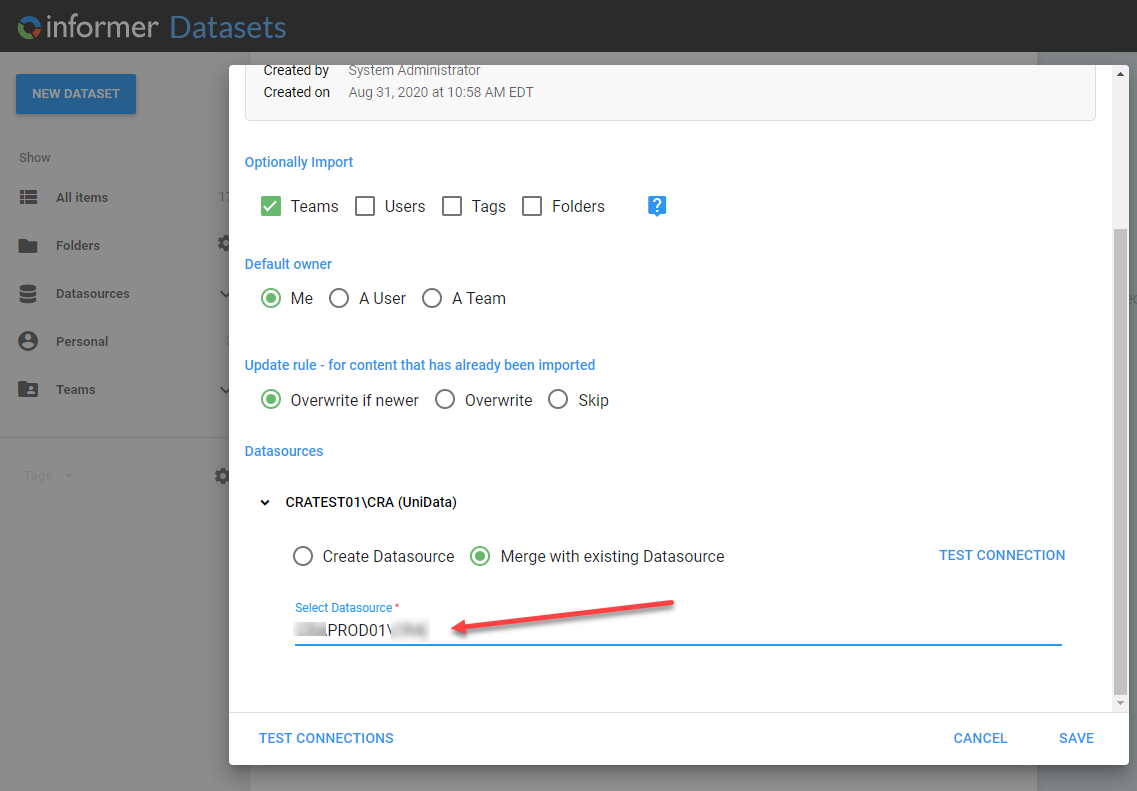
Once you drop this file in the Dataset window, it will pop up with a dialog where you can set the options for the import.
You can choose to import items like Teams, User, Tags or Folders.
You can also change the default owner.
You will want to leave the Update rule to "Overwrite if Newer".
And lastly, if you want this imported Dataset to point to a new datasource, then change the datasource listed in the "Select Datasource" section.
You want to also leave it as "Merge with existing datasource".
Click on Save and then verify that the new Dataset has been created.
I have seen times where if steps are not followed, that the target Datasource may get renamed. If this ever happens you simply need to rename the Datasource back to its original name.
Creating a Datasource Link
If you have two mappings that are not linked, but do have a field in common, you may create your own link in Informer.
- Go to Datasources
- Select the Datasource with the mappings you want to link and double click it. If you have Prod, Test and/or Dev environments, you will need to create the link for each environment that you need it in.
- Click on the link icon (second icon from the top) at the very left panel.
- Click on "New Link" and choose how you want to link your mappings.
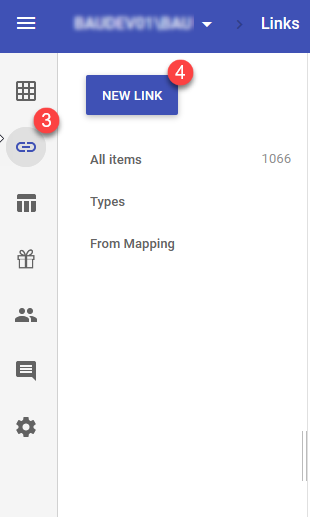
At the datasource page, click on 'New Link' and Select "U2"
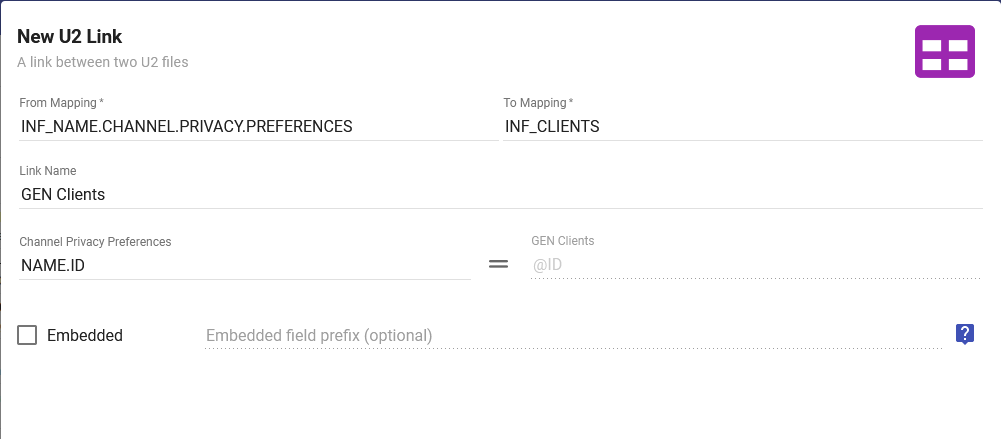
Populate the 'From Mapping' and 'To Mapping' with the mappings you are trying to link in the system. These are the Files on the U2 side of things.
Provide a 'Link Name' for the link. This is how the link will appear if you try to search for it in the system and when you are navigating through your various mappings when building out a Dataset.
Select the field in the 'From Mapping' file that will match up with the @ID field in the 'To Mapping' file.
Select whether or not you wish to embed this link. If a link is embedded, all of the fields in the 'To Mapping' file will appear as though they belong to the 'From Mapping' file when you are selecting fields to add to a Dataset.
I would recommend to not embed the link unless you really need it in the main table.
Click 'Save'
Security in Informer
Security in Informer is based on Teams and Users.
The primary uses of the Team/User security is to be able to control which Reports and Datasets a user has access to and also what they can do with the Reports and Datasets that they have access to.
Teams and Users by themselves are not that useful. It is when we add users to teams that we start to see the power of the security system in Informer.
To start, let us look at the attributes of Teams and Users separately.
Users
Users in Informer are created by the Naviga Ad system. To make this happen, log in to the Naviga Ad system and click on the Informer tile. This will open up Informer and if it is your first time in Informer, your user will automatically be created.
As part of this automatic creation, your user will be added as a Data Wizard to the default team predefined for your site.
So what is a Data Wizard? When you add a User to a Team, you must assign them a Role on that team. The Role defines what the user can DO with the items they will have access to by being part of the team. See the Roles a User can have on a Team.
The Data Wizard role is able to do many things, so you may want to adjust this role for some users. Here are the main "power" features of a Data Wizard:
- Create their own Datasets.
- Edit any Dataset or Report owned/shared to the Team.
When a user is created, it is given the Normal User permission. This is what most users should be. The other additional attributes that you can add the the Normal User permission are:
- Job Creation - The ability to create Jobs.
- Painless Script Creation - You can ignore this option.
For system administrator users, you will change their permission from Normal User to Super User.
Super Users have full access rights to the entire system, superseding any Team-based Role assignment. A Super User can view all content within the system, including all fields within a Datasource, and can modify any Datasource, Dataset, Report, or Job.
Very few users should have Super User access.
Teams
A team is simply a container for a group of users. Many sites set up teams to mimic divisions within their company.
When Informer is first set up for your site, a single team is created and all users automatically get assigned to this team with the Role of Data Wizard.
User Roles on Teams
As stated before, the flexibility in the security structure is made possible by assigning roles to users as you add them to different teams.
Here are the different roles that you can assign a user when adding them to a team.
| Role Name | Rights |
|---|---|
| Member | View anything Owned by the Team |
| Designer | All Member rights Create content from Datasets available to the Team Upload spreadsheets into new Datasets Create Reports from Datasources available to the Team Create and manage Tags |
| Data Wizard | All Designer rights Create Datasets from Datasources available to the Team Create Workspaces Edit Team-owned Datasets Promote their private Dataset filters to public. |
| Publisher | All Data Wizard rights Share Team-owned Datasets and Reports to other Teams. Generate external links to Visuals and Reports Create access tokens Create one-off Bundles of Team-owned Datasets and Reports |
| Admin | All Publisher rights Manage members Create any type of Datasource Share a Team-owned Datasource to other Teams Create one-off Bundles of Team-owned Datasources |
It is good to understand that if a resource (Dataset, report, etc) is shared with multiple teams and a user is a member of each of those teams, the most advanced user role that the user has will take precedence.
For example, if you have TeamRep and TeamAdministrator teams with a user named User_One that has the following user role assignments for each team:
- TeamRep
- User_One - Member Role
- TeamAdministrator
- User_One - Publisher Role
Consider that we have a Dataset shared with both of the above teams. When User_One goes to view that dataset, they will view it with the Publisher Role because that is the greatest role for them on that Dataset.
This is an important consideration when setting up complex security scenarios with users existing in multiple teams, giving you great flexibility, but also requiring you to spend some time fully mapping out what you want to get out of the security.
Limiting Data by Team Assignment
You can also use Team assignment to limit data in datasets.
For example, if you had two teams, Team Division 1 and Team Division 2. Each team will have users assigned to them and we want to be able to use these teams to limit data seen by users of the teams.
This is done at the level of Sharing a Dataset.
When you create a dataset, you have the options to share that dataset with teams or users. When you share the dataset, you have an additional option of being able to share it to a team, but only certain data.
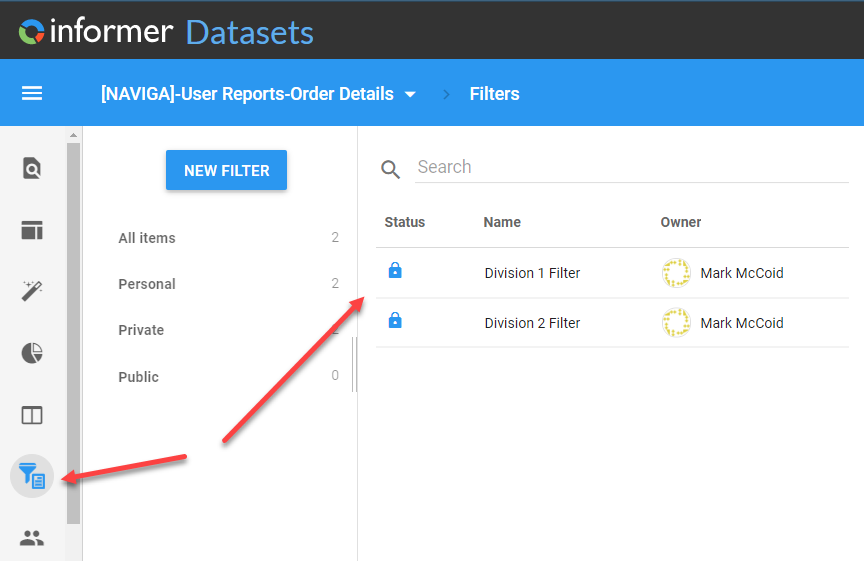
The way you specify which data is through a filter.
First, you create the filters that will be used to limit the data when sharing. Here I have created two filters, one that limits data for each team that I am working with:
Next, you will need to Share the dataset with the appropriate teams.
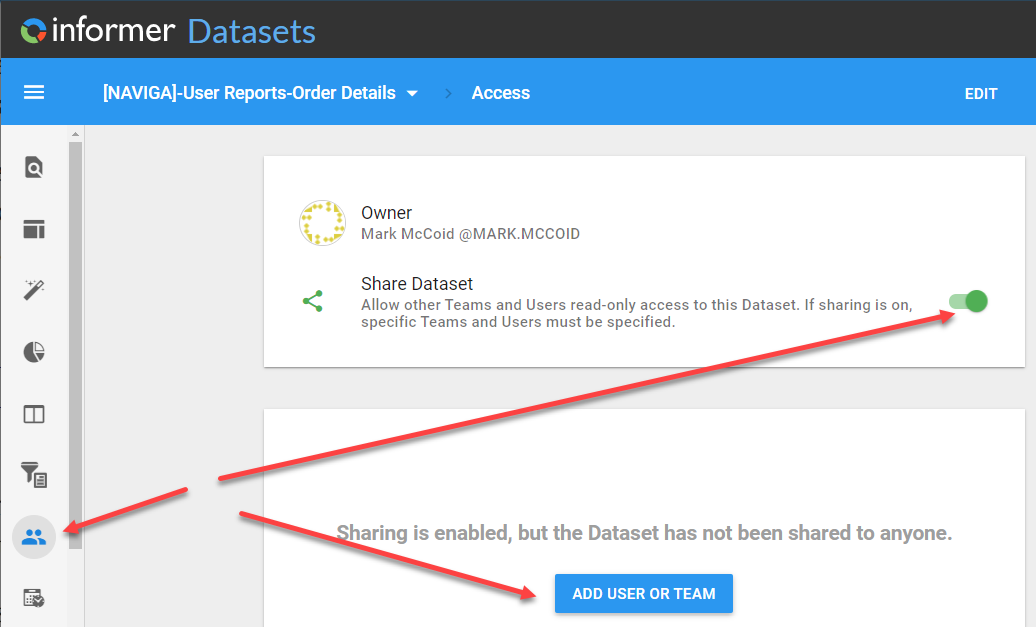
The dialog that you see when you press ADD USER OR TEAM is where the magic happens.
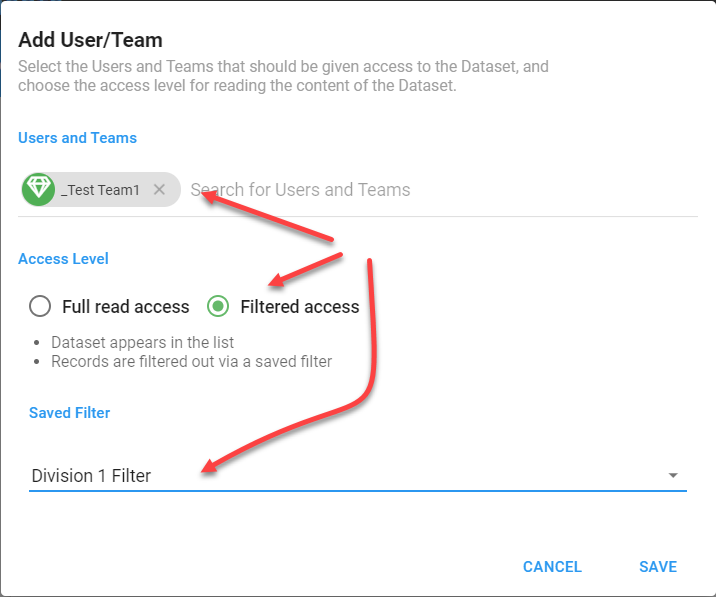
You can, and will, add multiple teams. They important part is that for each team, you select Fitered access and choose the filters that you want to be applied when any user of the team view the dataset OR a report that uses the dataset.
This becomes a very powerful tool, but again, though needs to be put into the team structure and how the filters are to be constructed to make sure the proper outcome is achieved.
Questions When Converting from v4 to v5
Informer 4 allows for input parameters to be set on the schedule
I am assuming this means setting some sort of filtering criteria for what will be emailed/exported for a job.
If the Job's data is an Ad Hoc Report and it has query Inputs associated with it, when you create a Job with that report and click on run the Job editor window, you will be presented with the Query Inputs dialog, where you can enter the inputs.
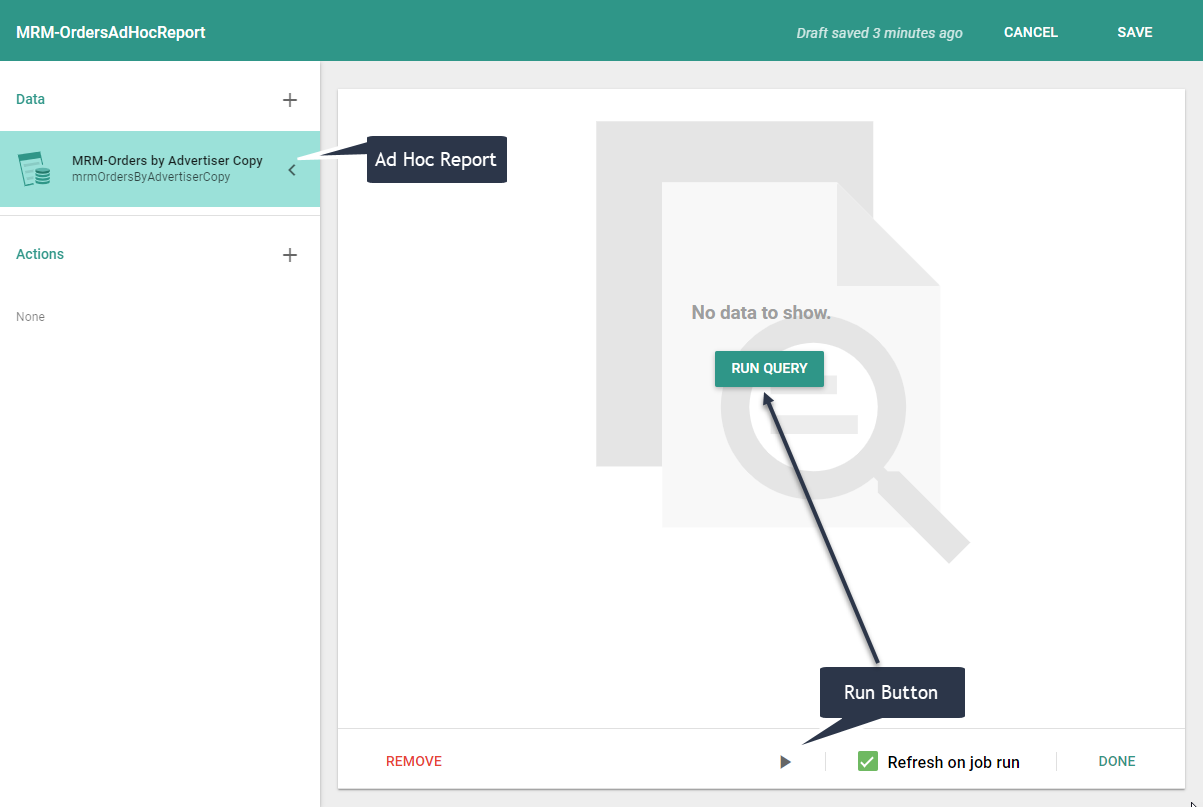
When you click on run, you will see the Inputs dialog:
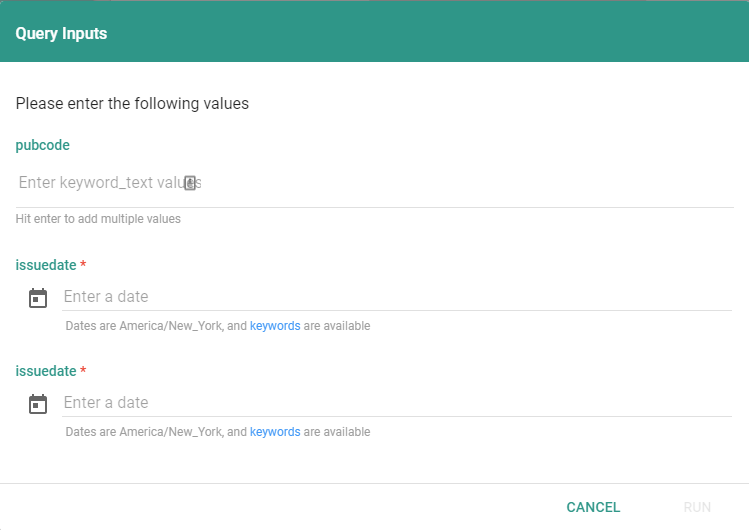
Whatever you enter as inputs will be used on all subsequent runs of the Job.
Datasets
You can do the same with a Dataset, but the standard practice with a dataset will be to have one job that reloads it and the other jobs that use a post filter, to narrow the data and set to the appropriate users.
Post Filter
Many times, your need to only set a select set of data to users can be accomplished using a Post Filter or by using an action such as the "Sen an email burst".
The post filter is located here: