Informer Rest API
API Basics
Informer Base URL
https://xxxbi.navigahub.com/api/
Route
xxxbi.navigahub.com/api/datasets/OWNER:datasetname/data
Options
xxxbi.navigahub.com/api/datasets/OWNER:datasetname/data?start=0&limit=50
You will find that the Routes fall into two basic categories, either Datasets or Ad Hoc Query Reports.
The main difference is that when you request data from an Ad Hoc Query report, it must execute the query against the Naviga database and then return the data. The Dataset data is cached, so when you request data from it, you will be getting the last refreshed data. This makes datasets the most performat of the two options.
Dataset Routes
GET - Request Data
The route that is used to get data from a dataset. Replace the {id} with the id of the Dataset.
/datasets/{id}/data
There are two options when getting the {id} for the dataset. You can either get a unique UUID or you can get the user:name-of-dataset.
The UUID is the best for stability, as renaming the Dataset will not affect this id.
The easiest way to get the correct text id for the dataset is to open the dataset in Informer and copy the id from the browser URL bar. Below, you would copy admin:api-book-invoice-detail as the id:
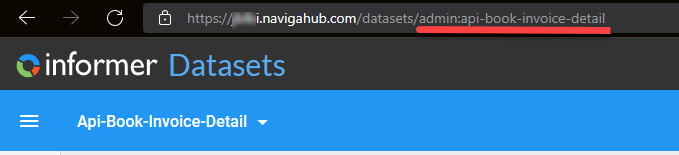
To get the UUID you will simply go to the Datasets area where you get a list of all of your dataset and select the dataset you want the UUID for. It will be listed in the right sidebar and will be called "ID":
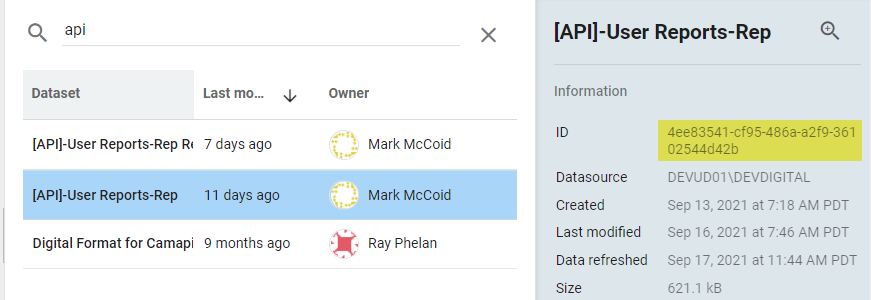
Useful Parameters
You have some optional parameters that you can include via the query string, most useful are:
?start=0&limit=50&sort=_doc
These options will allow you to tell the API what data you want to retrieve from the dataset. This is very useful if you need to limit the amount of data coming back.
It also facilitates paging through the data. The sort parameter can be any field, but the most performat way to run it is by using the _doc field, which is an ElasticSearch field (you won't find it in your results).
NOTE: According to Entrinsik, if you don't need to sort by any specific field, then you should always include the sort by _doc option:
sort=_doc
Filtering the Dataset
There are two other optional parameters that you can use if you want to filter the data coming back.
- q - allows for simple filter on a single field - q Parameter Details & Examples
- filter - allows for more complicated filtering using the ElasticSearch Query DSL. filter Parameter Details & Examples
API Results JSON
{
"_links": {
"self": {
"href": "https://devbi.navigahub.com/api/datasets/MARK.MCCOID%3Ainf-temp-user-reports/data?start=0&limit=50"
},
"next": {
"href": "https://devbi.navigahub.com/api/datasets/MARK.MCCOID%3Ainf-temp-user-reports/data?start=50&limit=50"
}
},
"items": [
{
"LineNetAmount": 3000,
"RevenueDate": "2021-10-01T07:00:00.000Z",
"a_d_internet_gl_types_assoc_desc": "Print Display",
"advName": "Flying Toasters",
},
{
"LineNetAmount": 2304,
"RevenueDate": "2021-08-01T07:00:00.000Z",
"a_d_internet_gl_types_assoc_desc": "Print Display",
"advName": "FAY DRIVE BREWERY",
},
...
],
"start": 0,
"count": 50,
"total": 1898
}
The data will be in the items key and presented as an array of objects.
If you are paging through the data, then you will want to take note of the _links key. It will have a next key that contains the next start/limit options set up for you. It will also have a _prev key if needed and when you hit the end of the dataset data, the _next key will no longer be available.
The _prev and _next links take into account the initial limit value that you sent. For example, if you sent ?start=0&limit=100, the _next link would have the following query params ?start=100&limit=100
If you are using the next or prev, you can add the &sort=_doc.
GET - Export JSON
This is a great route if you don't need to page through the data and you just need all of the records.
/datasets/{id}/export/{exporter}
The most common exporter is json. If you want to see the other options, you can call this endpoint (GET):
/datasets/{id}/exporters
There are a few other parameters that are optional.
omit - If you do not want certain fields to be included in the output, add an omit paramter for each field to omit:
/datasets/{id}/export/json?omit=productId&omit=productNameinclude - If you only want certain fields to be included in the result, add them here. Note that you should not use both omit and include, choose one and use it if needed.
sort - sort by fields indicated. As with
omitandincludeif you need to sort by multiple fields, then add multiple sort paramters:/datasets/{id}/export/json?sort=productId&sort=productNameq - allows for simple filter on a single field - q Parameter Details & Examples
filter - allows for more complicated filtering using the ElasticSearch Query DSL. filter Parameter Details & Examples
POST - Refresh Dataset
To programatically refresh a data use the following Route:
/datasets/{id}/_refresh
If you have Input values that you want to pass for the refresh, you can pass them in the body of the post as a JSON object:
{
params: {
nameOfInput: ["value", ...]
otherInput: [...]
}
}
Note: The type of input that you defined in the Dataset itself doesn't matter. For example, if you had defined an input as "Only allow a single value", you could still pass multiple values through the body and the refresh would use those values. The input dialogs you build on the dataset ONLY control what gets sent to this api. They are only a UX on top of this API. THey will not limit what you send.
Example of a raw JSON body sending a date and a campaign ID to the refresh:
{
"params": {
"startDate": ["09/01/2021"],
"campaignId": [6736, 6796]
}
}
GET - Request Params
/api/datasets/{id}/params
This will return the last used set of params (input fields) for this dataset. In the example result below, you will see that it had an input field startDate that was used:
{
"_links": {
"self": {
"href": "https://devbi.navigahub.com/api/datasets/MARK.MCCOID%3Aapi-user-reports-rep/params"
}
},
"startDate": [
"MONTH_BEGIN-1M"
]
}
NOTE: The returned params list does NOT include all input values, ONLY the ones that were used on the last refresh of the Dataset.
GET - Dataset Info
The mother of the dataset requests will return all metadata information about a Dataset.
/api/datasets/{id}
You will have to play around with the returned JSON to find what you need, but one of interest will be the \_embedded.inf:query.settings.inputs which will give you a list of all available inputs, versus the Params, which will only give you inputs that were used on the last refresh.
{
"_links": {},
...
"_embedded": {
"inf:field": [],
"inf:query": {
"_links": {},
"naturalId": "694c8c1f-dec1-47fc-83eb-8c7c8eff6e0c",
"permissions": {
"assignTags": true,
"changeOwner": true,
"copy": true,
"delete": true,
"edit": true,
"rename": true,
"revisions": true,
"run": true,
"share": true,
"write": true
},
"id": "694c8c1f-dec1-47fc-83eb-8c7c8eff6e0c",
"tenant": "manager",
"ownerId": "MARK.MCCOID",
"slug": null,
"name": null,
"description": null,
"shared": false,
"embedded": true,
"source": null,
"sourceId": null,
"settings": {
"grid": {},
"chips": [],
"filter": {},
"useFakeData": false
},
"inputs": {
"multiInput": {
"inputs": [
{
"name": "startDate",
"type": "Input box",
"label": "startDate",
"component": {
"mdMultiInput": {
"type": "text",
"wildcard": false,
"delimiter": "comma",
"onlySingle": false,
"defaultValue": [
"MONTH_BEGIN-1M"
]
}
}
},
{
"name": "campaignId",
"type": "Input box",
"label": "IN Campaign ID",
"component": {
"mdMultiInput": {
"type": "text",
"wildcard": false,
"delimiter": "comma",
"onlySingle": true
}
}
}
],
"instructions": ""
}
},
"language": "informer",
"flow": [
{
"script": {}
},
{
"removeField": {
"fields": [
"netCost"
]
}
}
],
"payload": {},
"defnUpdatedAt": "2021-09-16T14:46:21.889Z",
"fields": {},
"limit": -1,
"createdAt": "2021-09-13T14:18:49.174Z",
"updatedAt": "2021-09-16T14:46:21.890Z",
"datasourceId": "538e966c-cbb9-42c6-830a-b228a91dbaaf",
"editingId": null,
"folderId": null,
...
},
"inf:datasource": {},
"inf:filter": []
}
}
GET - Index Count (Number of Rows in Dataset)
This route will return an integer with the count of rows in the dataset index.
/datasets/{id}/index/count
Report Routes
POST - Request Data
This route will run the report and return the data. Many reports have required or optional parameters and these can be sent in the body of the Post request.
The base route is:
/queries/{id}/_execute
Other Information
q examples
You can filter on a single field using the q parameter. If you need multiple values, separate them by a space
q=campaignId:6736
OR
q=repName="Rep Name"
Here is an example:
...&q=repName:"Donna Beasley" "Kelly Smith"
filter examples
The filter param must be a valid JSON string. The filter is actually an query built using the ElasticSearch Query DSL.
The Query DSL is complicated in its own right, so I will just give you a few simple examples, but do explore the documentation above for more details.
Only return campaignId in 6736 or 6796
{
"bool": {
"filter": {
"terms": {
"campaignId": [
6736,
6796
]
}
}
}
}
// You would send without formatting:
{"bool":{"filter":{"terms":{"campaignId":[6736,6796]}}}}
OR using a Match query:
{
"match": {
"campaignId": 6736
}
}
// You would send without formatting:
{"match":{"campaignId":6736}}